Ich habe ein Problem. Ich bin jetzt quasi mein ganzes Erwachsenenleben Wissenschaftler und ich habe immer noch keinen guten Weg gefunden, sinnvoll mit Informationen umzugehen. Das Grundproblem der ganzen Übung ist folgendes. Wir leben im Informationszeitalter: Es gibt zu viel Informationen, die über teils ganz verschiedene Kanäle zu uns kommen. Diese Informationskanäle sind zudem oftmals nicht kompatibel zueinander weil alle ihre Abo-Modelle und „walled garden“ Mentalitäten pflegen. Das ganze ist quasi ein Input-Output Problem: vorne kommen ganz viele unstrukturierte Daten rein die dann am Ende im Output, akademischen Publikationen münden sollen. So die Theorie. Nur gibt es dafür „in this day and age“ keine gute Lösung, oder?
Eine Flut verschiedener Quellen
„Früher war alles einfacher“ ist natürlich eine Phrase, aber im akademischen Kontext stimmt das wohl. Es gab weniger akademische Journals und Bücher waren das Nonplusultra. Wer einen Überblick über ein Thema haben wollte, hat ein Handbuch gelesen. Heute ist Wissenschaft komplizierter. Wissenschaftler beziehen heute alle Informationen aus sehr unterschiedlichen Quellen.
Da wären die klassischen akademischen Journals, in denen Fachaufsätze der jeweiligen Disziplinen veröffentlicht werden. Man bekommt diese Information in der Regel die folgenden Kanäle: Oldschool-Wissenschaftler haben ein physisches Abo und lesen die neueste Ausgabe in Print oder bekommen Sie von ihrer Uni-Bibliothek. Alternativ man wird per Email-Newsletter über eine neue Issue informiert und erhält darin zum Beispiel das Inhaltsverzeichnis.

Viele Journals kommunizieren neue Ausgaben samt Inhaltsverzeichnis auch über Twitter oder Facebook. Natürlich surfen auch manche Leute noch manuell einmal im Quartal alle wichtigen Journals an oder gehen in die Bibliothek. Für mich ist das zu umständlich, denn es gibt ja nicht, wie früher, nur wenige, wichtige Journals, sondern dutzende. All diese Journal Websites manuell einmal pro Quartal aufzurufen ist mir zu ineffektiv, da ich dutzende verschiedene Journals verschiedener Teildisziplinen lese (Science & Technology Studies, International Relations, Political Science, Cyber-Security, Computer Science etc.). Zum Vergleich: ich „lese“ 33 verschiedene Journals. Wenn ich pro Journal 5 Minuten Zeit im Quartal zum „screenen“ und selektieren der wichtigsten Beiträge zur Weiterverarbeitung einplane, bin ich 165 Minuten, also gut 3h beschäftigt. Das ist optimistisch, da die Journals über unterschiedliche Publisher gehen, die jeweils eigene Website Layouts haben. Manche davon sind übersichtlicher als andere. Bei manchen muss man umständlich über Web-Logins auf Bestände zugreifen (I’am looking at you, Nomos). Die fortschrittlichen, amerikanischen Journals bieten RSS-Feeds an, die Informationen direkt zu mir „pushen“. RSS ist eine der am wenigsten „geschätzten“ und zeitgleich mächtigsten Internet-Technologien. Die Rückständigen, deutschen Journals bieten oft nur Emails an, argh (again, I am looking at you, Nomos!). Das heißt hier fängt das Chaos schon an, weil allein das Wissen darüber, was gerade in Journals erschienen ist, schon über zig Kanäle kommt: per Browser, Mail, Twitter und RSS.
Ich lese aber nicht nur Journals, da die nicht die einzige Wissensquelle sind. Think Tanks weltweit publizieren oft hochqualitative, graue Literatur in höherer Geschwindigkeit als Journals. NGOs und freie Forschungsinstitute wie Fraunhofer, das kanadische Citizen Lab etc. tun das auch, jeweils wieder über zig Kanäle. Dazu gibt es eine Reihe namhafter Blogs (Bruce Schneier, Krebs on Security etc.) sowie Reports von IT-Sicherheitsfirmen, die es auch zu lesen gilt. Auch hier gibt es wieder zig Varianten. Die meisten Organisationen bieten E-Mail-Newsletter an, andere auch RSS-Feeds. Dazu kommen Newsletter-Listen von Fachcommunities (IB-Liste etc.), auf denen Wissenschaftlerinnen Call for Papers, Konferenzen und Publikationen einstellen. Dann gibt es ja auch noch die Fachorganisationen, wie Verbände (Deutsche Vereinigung für Politikwissenschaft, European Consortium for Political Research) oder Kammern, die auch noch Informationen per E-Mail verteilen.
All das reicht aber nicht um up-to-date zu bleiben. Die Arbeit in einem Think-Tank bedeutet, tagesaktuelle Entwicklungen zu verfolgen um wissbegierigen Journalisten (Grüße!) Rede und Antwort zu stehen, wenn mal wieder ein Staat einen anderen hackt. Das bedeutet ein tägliches Abklappern zahlreicher Newsseites (Süddeutsche, Spiegel, Zeit etc.), aber auch spezieller IT-Security News-Sites (Cyberscoop, Darkreading, Cipherbrief). Dann muss man auch noch wissen, was die Bundesregierung so denkt und liest daher Antworten auf kleine Anfragen oder Papiere des wissenschaftlichen Dienstes. Aufgrund dieser Informationsflut und Informationsdiversität im Cyber-Sicherheitsbereich haben zudem zahlreiche Zeitungen angefangen, Newsletter Digests anzubieten. So bekommt man ein oder mehrmals die Woche kurze Sammlungen der relevanten News der Woche (Politico Morning Briefing oder sowas wie Tagesspiegel Background Digitalisierung). Die gehen auch über Email. Soweit so gut.
Was ist mit Twitter? Ich bin großer Verfechter von „academic twitter“, d.h. der rein akademischen Nutzung (naja und random Gifs, ok, ok!) von Social Media.

Das bedeutet, du folgst nicht deinen Freunden und Nachbarn und teilst keine Katzenbilder (oder nur sehr wenig) oder Fotos von Essen, sondern folgst nur akademischen Kolleginnen und Kollegen bzw. allen, die interessante Informationen posten. Ein Großteil aller Informationen meines Faches beziehe ich aus meiner Filterbubble (I love you nerds!). Das ganze ist hervorragend schnell und aufgrund meiner recht strengen “following” Regeln auch einigermaßen durchstrukturiert. Einige Koryphäen der IT-Security Community wie @thegrugq sind nur auf Twitter und posten da interessante Dinge. Ich benutzt Twitter ausschliesslich für die Arbeit und nach Feierabend vermeide ich es auch, da rein zu gucken. Twitter ist insofern gut, weil man das mittels Listen gut den eigenen Themen anpassen kann. Hartgesottene benutzen zudem TweetDeck und folgen ähnlich wie Stock-Broker 10 Feeds gleichzeitig. Das ist mir allerdings zu krass. Twitter ist leider nicht ganz so einfach mit der Informationsweiterverbeitung. Die Informationen über Twitter kommen in der Regel über Links, d.h. man landet viel auf Websites und extrahiert Informationen von da.
Kurzum: man hat extrem viele Informationen über extrem viele, verschiedene Kanäle: E-Mail, RSS, Twitter, Websites, die auch noch in verschiedenen Datenformaten, als Roh-Text, als PDF Dokument, als HTML usw.. zu einem kommen. It’s a mess.
Wissensproduktion im Zeitalter der Digitalisierung
Die ein oder andere wird sich jetzt fragen wo denn da die Bücher und die Zeitungen sind, die Politikwissenschaftler ja täglich lesen müssen (wurde mir im Studium eingetrichtert!). Physische Zeitung lese ich gar nicht und auch physische Fachbücher lese ich nur widerwillig, was evtl. den ein und auch den anderen Kollegen/Kolleginnen schocken wird. Das hat drei Gründe: 1) Sad-News, 2) Effizienz und 3) Umwelt.
Ein Großteil der heutigen News ist „depressing“. Die Aufmerksamkeitsökonomie buhlt um unsere Aufmerksamkeit und Populismus und Feuilleton-Trolling von vor allem, weißen, alten, latent-aggressiven Männern “ just wanting to watch the world burn“ machen schlechte Laune. Einen Großteil der Informationen in Zeitungen will ich auch gar nicht wissen (Sport, Mode, Autos, Trump, Johnson). Andererseits brauche ich aber die Informationen, die für mein Fach nötig sind. Das bedeutet, dass ich eine andere Art des Zeitungslesens brauche. Dazu später mehr.
Das profundere Problem, was ich mit Zeitungen habe ist, dass mir physischer Text schlicht zu ineffizient ist. Das ist hardcore neo-liberal gesprochen, also „let me explain“: Was machen Akademiker den ganzen Tag? Sie lesen Texte und verarbeiten die Informationen darin weiter zu neuem Text. Diese Informationsverarbeitung geschieht in der Regel in Form von Notizen, Anmerkungen am Text und Text-Exzerpten. Diese Medien sind die Träger von Ideen. Wissenschaft ist meiner Meinung nach die Kombination dieser verschiedenen Ideen in einem neuen Text, der das Ergebnis des gesamten Prozesses ist. Ich vertrete die These, das wissenschaftliches Denken „remixen“ ist.

Keine Idee ist für sich genommen originell. Nur die innovative Kombination mehrerer, bereits existierender Ideen erschafft neues Wissen. Der Gedanke von Autorin A, plus die Einordnung von Text B, und die Kritik daran von C, dazu noch ein Zitat von Autor D, um das ganze abzurunden. Während der Kombination der Textideen entstehen im Kopf neue Gedanken, die man dann aufschreibt. Die Kombination von Texten und somit die Wissensgenerierung funktioniert meiner Meinung nach am effizientesten, wenn alle Input-Texte auch digital vorliegen. Wenn ich Texte in verschiedenen physischen und digitalen Formaten vorliegen habe, wird die Informationsverarbeitung komplexer und erzeugt Reibung. Ein Beispiel:
Idee A habe ich evtl. auf einen Post-It Zettel geschrieben, den ich gerade nicht mehr wiederfinde. Für Einordnung B muss ich das Buch vor mir liegen haben, was aber immer wieder von alleine zu fällt, weil es eine doofe Bindung hat. Zudem hat wieder irgendjemand den Schreibtisch nicht aufgeräumt, tzzzzz. Für Kritik C habe ich evtl. einen Stapel lose Kopien, die über den Tisch fliegen, wenn der Wind durchs offene Fenster bläst. Und wo war nochmal das coole Zitat von Autor D? War das in Band 3 oder Band 4 der je 500 Seiten langen Abhandlung? Oder war das vielleicht gar nicht Autor D, sondern Autor E und ich verwechsle das gerade? Physischer Text produziert Reibung. Man kann ihn nicht nach Schlagworten durchsuchen. Er verbraucht Platz. 500 Aktenordner mit Kopien im Schrank zu stehen haben ist in Zeiten des knappen Wohnraums auch nicht optimal. Bücher die einem nicht gehören, kann man auch nicht bunt anmarkern. Da ich ein elaboriertes, „color coding“ System für Texte habe, sind für mich Bibliotheksausleihen mit einer Hassliebe verknüpft. Kurzum, digital ist besser.
Deswegen nutze ich, wenn ich dann doch Bücher lese, digitale Versionen. Also entweder per PDF, Epub, oder per digitalem Scan einer physischen Kopie, aber bitte mit OCR (optical character recognition). Das ist auch nicht optimal und ein rant über Bücher-publishing mache ich vielleicht an anderes mal. Es gibt aber auch gute Dinge. Moderne Smartphones haben so gute, KI-gestütze Kameras samt Text-Scan Apps, dass das Scannen heute einfacher ist als früher. So gescannte Texte sind dann einfach digital weiterzuverarbeiten, weil sie durchsucht werden können und Textstellen einfach digital markiert werden können (in allen Farben des Regenbogens!).
Und lastly, digitale Bücher müssen nicht gedruckt werden, womit wir beim dritten Grund angelangt wären, warum ich Print-Medien nicht mag (also nur den Print-Teil, nicht den Medien-Teil). Das gilt im weitesten Sinne für alle akademischen Drucktexte. Wir drucken zu alle viel aus. Papierherstellung ist enorm CO2-intensiv und tausende Bäume müssen gefällt werden, um einen Stapel Papier zu erzeugen. Drucker-Toner sind auch nicht gerade umweltfreundlich. Die meisten gedruckten Texte werden nur wenige Male gelesen. Akademiker sind da besonders verschwenderisch: man druckt mal schnell den Redebeitrag des Kollegen aus, macht sich zwei Notizen um die für Kommentare, zum Beispiel in akademischen Kolloquien, bereit zu haben, und danach guckt man den Text nie wieder an. Das gleiche macht man dann mit gedruckten Journal-Beiträgen, die dann in einem Aktenordner im Schrank verschwinden. Das ist eine unnötige Verschwendung von Papier. Über E-Mail Ausdrucker muss ich sicher nichts sagen.
Soviel zum Thema digitale Wissensproduktion, aber eigentlich ging es ja um das Management all dieser Informationen
Das Problem „in a nutshell“
Wir haben also zahlreiche verschiedene Informationen, in verschiedenen Formaten, die wir über verschiedene Kanäle beziehen um sie digital weiterzuverarbeiten. Der Traum wäre ein einziges System zu haben, wo alle Informationen reinkommen und dann von dort aus weiterverarbeitet werden können. Das ist gleichzeitig eine Utopie, da sich verschiedene Player mit unterschiedlichen Interessen nicht auf einen Informationsstandard einigen werden. Wie schon gezeigt, ist das etwa bei Think Tanks und Journals schon schwierig: manche bieten nur E-Mail an, andere verschicken PDFs, wiederum andere bieten RSS-Feeds an. Insofern braucht es einen Dienst, der verschiedene Informationsformate integrieren kann. Das ganze sollte möglichst reibungsfrei, also ohne Übersetzungkosten funktionieren und nicht zu komplex sein. Es ist nervig, zig verschiedene Apps zu verwenden. Newsseiten haben ja mit der Unsitte begonnen, eigene Apps anzubieten, d.h. wenn ich mehrere Zeitungen digital lese, muss ich je eine andere App verwenden, die dann wieder andere Features und Nutzerinterfaces haben. Dabei gehen überall Zeit und nerven drauf. Ideal wäre auch, wenn das ganze datensparsam und privatssphäreschützend funktioniert. Ja, man könnte alles über Facebook Newsfeeds lesen, aber dann kuratieren eben Facebooks Algorithmen dass, was ich sehe. Dazu sollte das ganze Organisationsunabhängig sein, die Abhängigkeit von einem Unternehmen bzw. von einem Arbeitgeber sollten reduziert werden. Sprich, ich will die Lösung migrieren können.
Die Bastellösung
Ich glaube dieses System gefunden zu haben. Es besteht aus vier Komponenten:
- Einem dezidierten Email-Account für alles was Newsletter, Table of Content Alerts usw. ist. Damit wird nicht kommuniziert sondern nur empfangen.
- Einen RSS Dienst, der verschiedene Newssources bündelt, aggregiert.
- Dazu kommt ein Filterdienst, der es erlaubt RSS Feeds nach bestimmten Inhalten zu filtern.
- Einem RSS Reader der multi-Plattform auf iOS, iPadOS und MacOS läuft und meinen Lesestatus über iCloud synchronisiert.
Um das Newsletterproblem zu lösen, habe ich schon vor Jahren einen eigenen E-Mail Account eingerichtet, der nur Newsletter empfängt, und mit dem ich nicht schreibe. Akademiker wechseln oft ihre Uni-Emailadressen (befristete Verträge und Wissenschaftszeitvertragselend sei dank), weshalb ich schon schnell gemerkt habe, dass es nicht sinnvoll ist, Newsletter auf die Uni-Email-Adresse zu bestellen. Auch die Newsletter von Fachcommunities gehen auf den separaten Account. Manche davon schicken dutzende E-Mails am Tag (I’m looking at you IB-Liste), da sie aufgrund von Pfadabhängigkeiten alte, featurearme Plattformen wie Yahoo benutzen. Das heißt das in einer separaten Inbox zu haben, die mir nicht das E-Mail Postfach voll spamt, ist eine gute Idee.
Damit sind alle Informationen, die nur per E-Mail vorliegen, schonmal gebündelt. Alternativ könnt man auch einen E-Mail Client wie Airmail nutzen, der dynamische, kombinierte Inboxen verschiedener E-Mail Adressen erlaubt. Da die meisten von uns aber in Windows-Welten leben (müssen) und das verkorkste Outlook benutzen müssen, empfiehlt sich die separierte Mail-Inbox-Lösung.
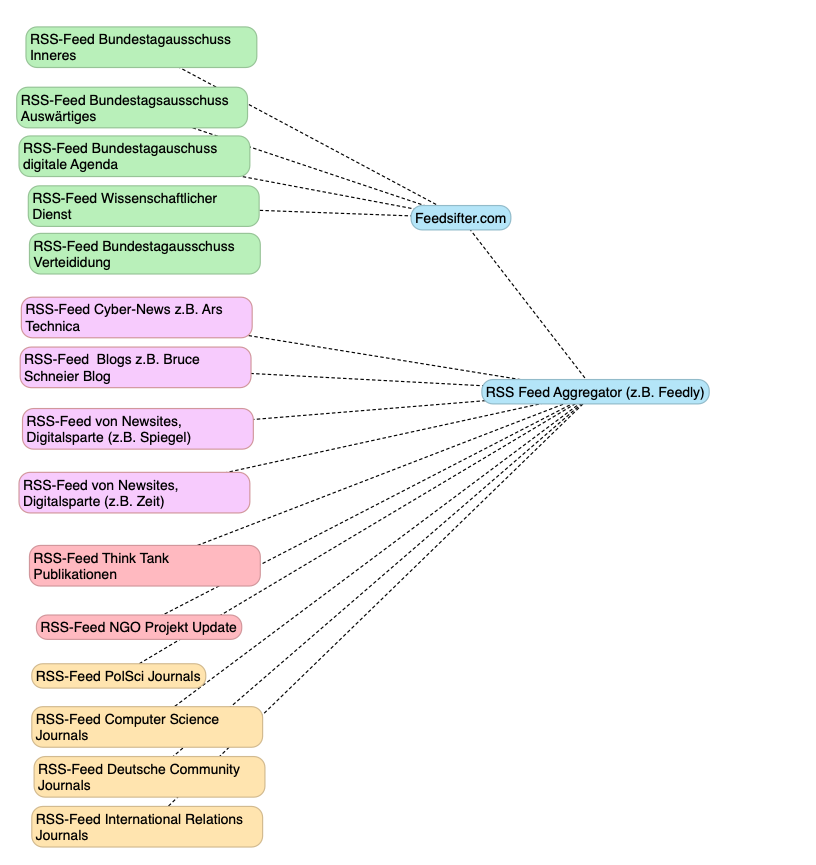
Die zweite Komponente ist ein Dienst der RSS Feeds bündelt, und in verschiedene Kategorien sortieren lässt. Hier gibt es zig Lösungen. Feedly ist ein ganz guter Dienst, er es erlaubt verschiedene RSS Feeds in Kategorien zu bündeln (ein Ordner für News-Seiten, einer für Journal-RSS, einer für Think-Tank RSS). Feedly erlaubt es daraus auch eine exportierbare Datei zu erstellen, die man über verschiedene Dienste importieren und exportieren, also mitnehmen kann. Allerdings speichert Feedly die Nutzerdaten und ist somit nicht ganz optimal. Aber Feedly ist ein Kann, kein Muss. Damit hätten wir die RSS Seite abgedeckt. Oder? Nicht ganz.
Wer den RSS-Feed des Bundestags, konkret der Ausschüsse, abonniert hat, dem ist evtl. schon das Problem der Korrekturbitten aufgefallen, die insbesondere von einer Partei kommen. Der Feed wird also vollgespamt mit Korrekturbitten, bzw. Informationen, die für mich nicht relevant sind. Mich interessieren zudem nur die Antworten auf die Anfragen, nicht die Anfragen selbst. Insofern habe ich den Dienst feedsifter.com dazwischen geschaltet. Das ist ein Dienst, der einen RSS-Feed modifiziert und z.B. bestimmte Inhalte rausfiltern kann. So sehe ich nur die Anfragen mit den Themen, wo bestimmte Schlagworte auftauchen. Das reduziert die Informationsflut.
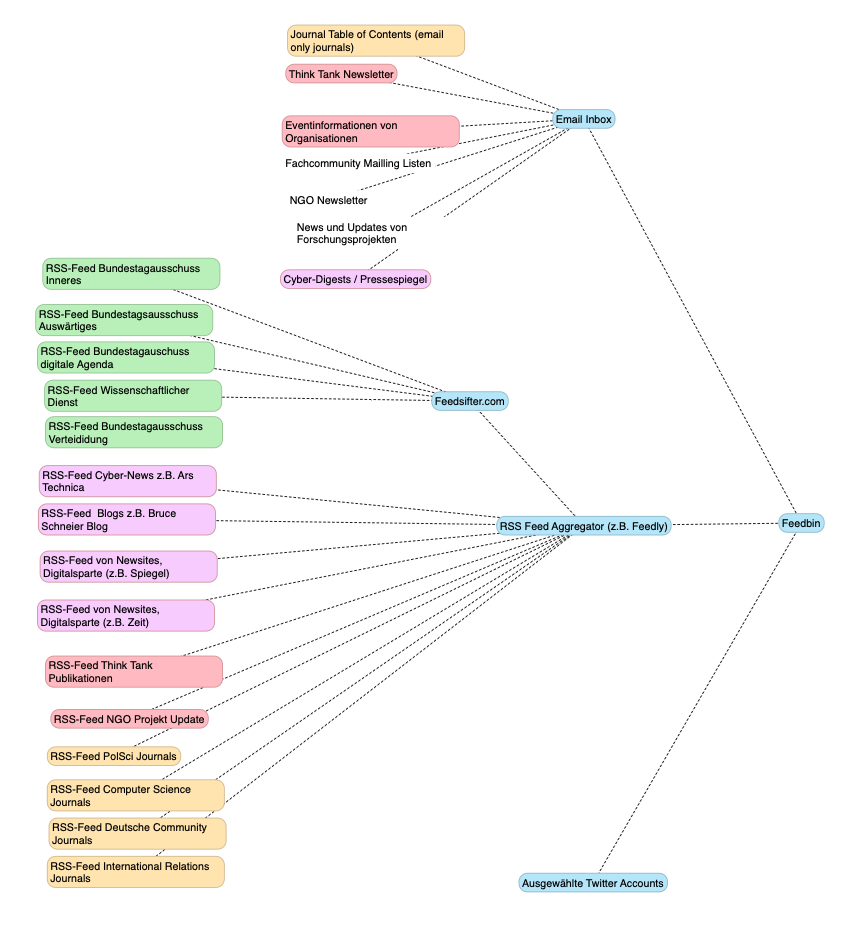
Jetzt fehlen noch Twitter und Social Media. Hier kommt jetzt ein kostenpflichtig Dienst ins Spiel, der Feedbin heißt. Im Grunde ist das eine erweiterte Version von Feedly. Zum einen erlaubt Feedbin das aggregieren von RSS-Feeds, und somit auch den Import von Feedly-Dateien. Gleichzeitig erlaubt Feedbin die Integration von E-Mail-, und von Twitter-Accounts. D.h. es ist die Plattform, die alle Informationen zusammen bringen kann. Der Dienst kostet 5$ im Monat, was total ok ist.
Die aggregierten Feeds können prinzipiell auf feedbin.com gelesen werden. Das ganze sieht auch ganz nett aus. Wie jeder RSS-Reader erlaubt Feedbin das anlegen von Ordnern mit Kategorien, und eine Durchsuchung des Feeds nach Schlagworten. Das erleichtert das wiederfinden von gelesenen News. Zudem kann man Favoritenlisten anlegen. Der Dienst markiert ungelesene, neue Nachrichten und entfernt die Markierungen beim lesen. So kann man mit den Cursor-Tasten schnell durch die Feeds scrollen, denn auch bei diesem optimierten System wird sich nicht vermeiden lassen, dass einem Inhalte angezeigt werden, die einen nicht interessieren. Das scrollen durch News geht aber um ein vielfaches schneller als das manuelle durchrufen dutzender Websites und des scrollens durch Artikel. In der rechten Spalte kriege ich den Full-Text, wahlweise auch als Plain-Text angezeigt. D.h. ich kann den Text markieren oder kopieren, wenn ich ein wichtiges Zitat sehe. Das erleichtert das digitale Weiterverarbeiten.
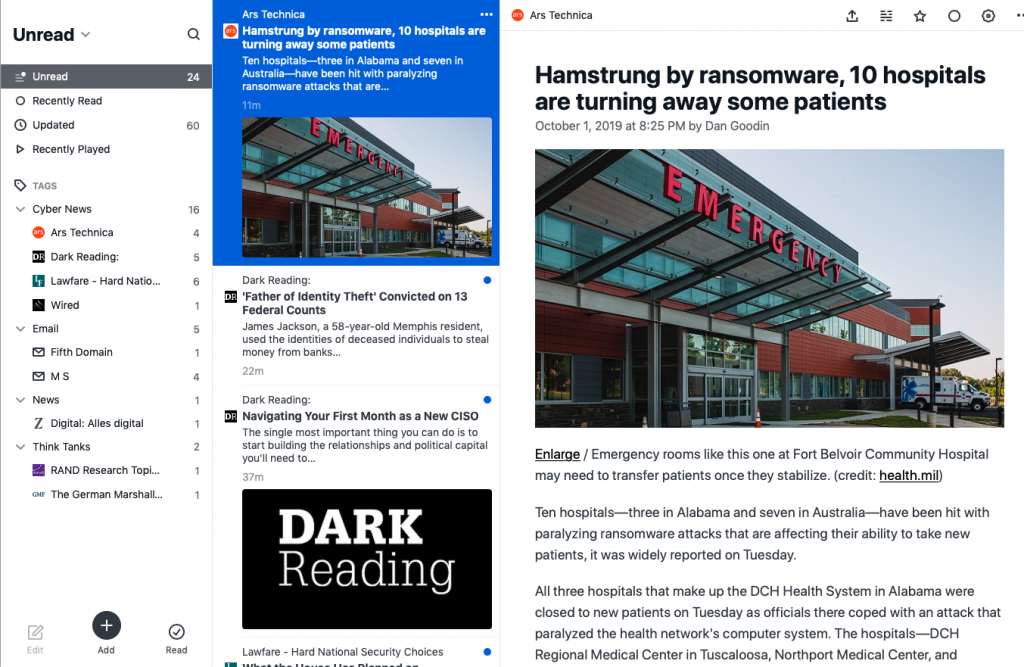
Auf diese Art und weise gucke ich mehrmals die Woche alle Feeds durch und markiere alles als gelesen bzw. markiere Favoriten, die ich evtl. später nochmal brauch. Damit löse ich gleich noch ein weiteres Problem, nämlich das der Archivierung. Feedbin erstellt mir eine History aller Informationen, die ich einmal gelesen habe. Das heißt, wenn ich mich in drei Wochen erinnere, dass ich doch da was über Ransomware in Krankenhäusern gelesen habe, schaue ich in meine Feedhistory und suche nach „Hospital“ und finde den Artikel und die richtige Seite wieder. Wenn ich per Hand alle Newsseiten absurfen müsste, würde das bedeutend länger dauern.
Die Feedbin Website ist schon ganz nett, aber die wahre Killerapplication ist m.E. die Integration in Third-Party Multiplattform Feedreader wie z.B Reeder. Reeder ist meine Lieblings RSS App sowohl auf iOS, iPadOS und MacOS. Sorry Android Guys, aber ich denke es gibt gute Alternativen. Ich benutze also Reeder mit eingebundenem Feedbin-Feed auf allen Plattformen gleichzeitig und dank Synchronisationsfähigkeit, kann ich meine Leselisten von verschiedenen Devices abarbeiten.
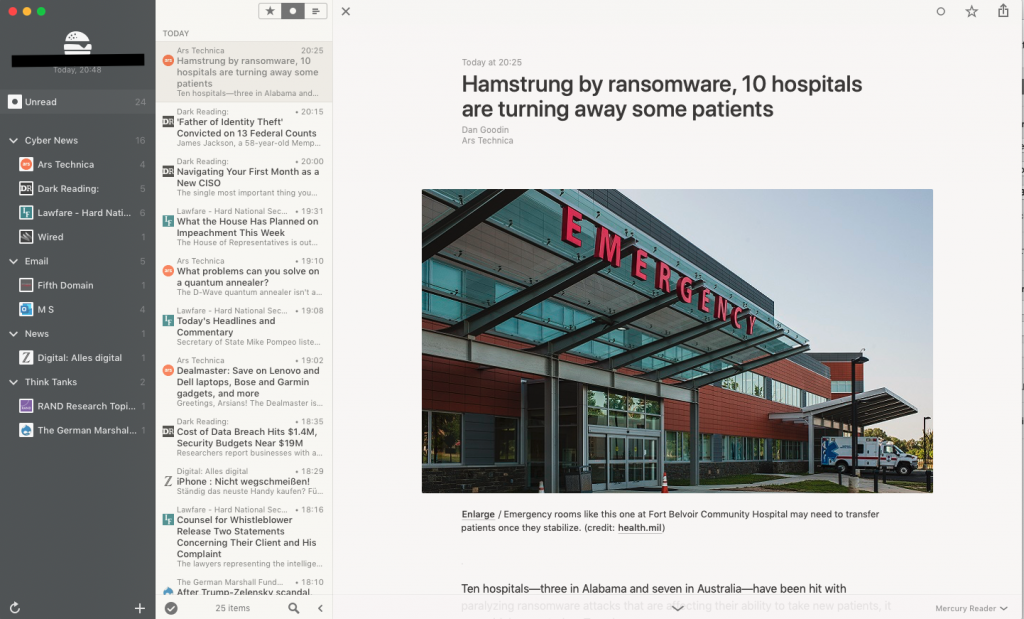

Feedbin iOS Start screen Feedbin iOS Settings Feedbin iOS Settings
Mir gefällt insbesondere die Usability und das Design von Feeder. Es gibt zahlreiche Funktionen, die App den eigenen Bedürfnissen anzupassen. Typografie und Farben können angepasst werden und sind generell sehr Lesefreundlich. Durch Wischgesten kann man durch Swipes nach links bzw. Rechts Artikel blitzschnell als gelesen oder als Favoriten markieren. Ich markiere alle Artikel, die für mich interessant sind als Favorit. Damit erstelle ich eine Lese-History interessanter Artikel. Wenn ich mich also in 4 Monaten grob erinnere, dass ich doch da irgendwo was interessantes über, say „Quantencomputer“ gelesen habe, durchsuche ich einfach meine Favoritenliste und finde den Artikel wieder.
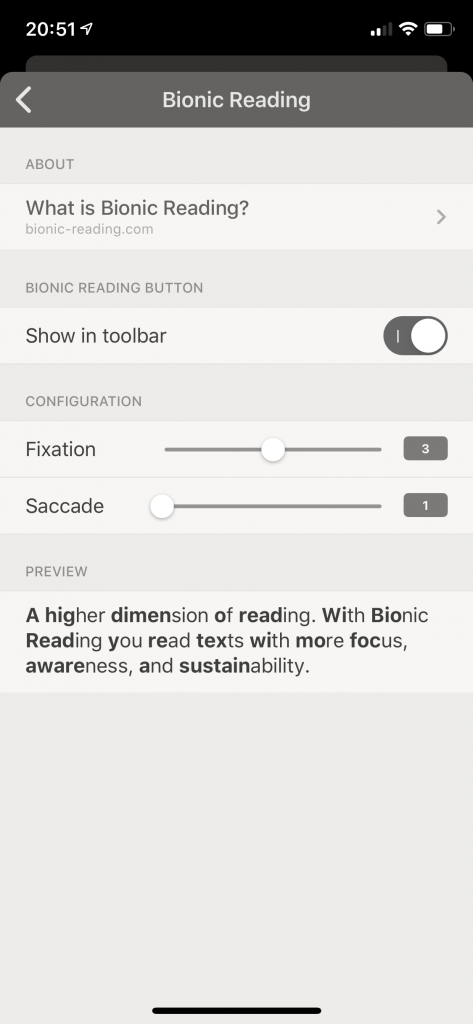
Wenn man einen ungelesenen Beitrag gelesen hat, verschwinden diese automatisch aus dieser Kategorie und werden als „gelesen“ markiert. Damit kann man sehr schnell „inbox Zero“ erreichen, also sich schnell durch eine sehr große Anzahl ungelesener Einträge wischen. So kann man schnell dutzende Einträge screenen. Bei so vielen Feeds kommen pro Woche hunderte Einträge zusammen, die sich so sehr schnell durchsehen lassen. Auf dem Mac kann man per Multitouch oder Tastatur scrollen. Ein interessantes Feature ist „bionic reading“, eine Funktion die bestimmte Textelemente highlighten kann, so dass man theoretisch noch schneller lesen kann, weil man eh nur den Anfang und das Ende von Wörtern liest und das Gehirn alles dazwischen interpretiert.
Diese Kombination dieser Dienste ersetzt für mich das, was in Behörden normalerweise Mitarbeiter machen, die Pressespiegel erstellen. Diese drei Dienste erstellen für mich einen sehr leicht-verwaltbaren Pressespiegel, den ich voll kontrollieren kann. Damit kann man selektiv up-to-date sein: man kriegt nur die Informationen, die man für die Forschung braucht und kann sich die 10. News über einen neuen Trump Tweet ersparen. Die Informationen können von überall, über alle Geräte gelesen und bearbeitet werden. Da alles digital vorliegt, kann es auch easy weiterverarbeitet werden. Feeder hat umfangreiche sharing Funktionen für weitere Dienste wie Pocket oder Evernote. Wie genau ich Infos weiterverarbeite, erörtere ich mal in einem weiteren Blog Post.
There is a catch
Da wir ja in Deutschland leben und alles mit Digitalisierung grundsätzlich suspekt ist, beruft man sich ja gerne auf den Datenschutz um eine bequeme Rechtfertigung zu finden, nicht auf neuere, effizientere Technologien umsteigen zu müssen. „Sorry, können wir nicht machen aus Datenschutzgründen. Deswegen bleiben wir bei Schreibmaschinen oder Fax“. Deswegen zwei Worte zum Datenschutz.
Feedbin wirbt damit, dass sie „privacy by design“ eingebaut haben. „Feedbin is private by design. There are no ads or tracking scripts. Feedbin also tries to protect your privacy while using Feedbin.“ Allerdings erhebt Feedbin natürlich alles, was ich lese und markiere. Die Datenschutzerklärung offenbart aber keine größeren Schweinerein und vor allem keine Weitergabe von Daten an Broker. Verglichen mit den Terms and Ccnditions von anderen Diensten lassen sich die von Feedbin innerhalb einer Minute lesen und verstehen. Dennoch bleibt der Beigeschmack, dass der Dienst all das aggregiert, was ich lese. Feedbin schlüsselt das auch recht detailliert auf.
Feedbins Privacy Policy liest sich wie folgt: We use the information we collect to operate and improve our website, apps, and customer support. We do not share personal information with outside parties except to the extent necessary to accomplish Feedbin‘s functionality. We may disclose your information in response to subpoenas, court orders, or other legal requirements; to exercise our legal rights or defend against legal claims; to investigate, prevent, or take action regarding illegal activities, suspected fraud or abuse, violations of our policies; or to protect our rights and property. In the future, we may sell to, buy, merge with, or partner with other businesses. In such transactions, user information may be among the transferred assets.
Damit lassen sich natürlich interessante Profile über meine Interessen erstellen, ähnlich wie Facebook und Twitter es natürlich auch machen, und ähnlich wie es z.B. Google Mail auch macht. Je nachdem welche Dienste man nutzt, kommt man da also nie ganz raus. Der Dienst speichert die Daten zudem außerhalb der EU, so there is a catch. Gleichzeitig ist zu erwähnen, dass Feedbin per Subskription Modell sein Geld verdient, und nicht durch das Einblenden von Werbung. Sämtliche RSS-Feeds sind also auch Werbefrei, was ein weiterer Vorteil der Nutzung ist. Die beiden Erschaffer von Feedbin schlüsseln in einem Blog auf, dass der Dienst Datensparsam entwickelt wurde und z.B. auf tracking Dienste, iFrames, Google Analytics und Third-Party Buttons (Facebook) etc. bewusst verzichtet wurde. Am Ende stellt sich die Frage, ob man dem Vertrauen will. Ich persönlich tue das, weil für mich die Funktionalität großartig ist.
Man könnte natürlich obfuscation Methoden wie random Email-Addresen und Custom-Billing Adressen nutzen, wenn man da ganz auf Nummer sicher gehen will. Technisch versierte können sicher auch durch eigene Skripte eine ähnliche Funktionalität erreichen.
Fazit
Ich benutze diese Kombination der Dienste jetzt gut ein halbes Jahr und für mich hat sich das ganze bewährt. Ich lese mehr Informationen und habe einen vollständigeren Überblick, ohne mich von der Informationsflut erschlagen zu fühlen. Ich erinnere mich noch, wie ich früher mich manchmal dazu zwingen musste, eine Runde durch alle relevanten Websites und Informationskanäle zu drehen. Browser aufmachen, URL abrufen, Artikel durchscrollen und das ganze grob mal 100 (je nach Quelle). Wenn ich da 1 Minute pro Quelle einplane, was wenig ist, ist man am Tag 1-2h allein mit News-Input beschäftigt. Mit Feedbin und Feeder kann ich das extrem schnell zwischendurch in der Bahn machen und den „pile of shame“ derjenigen Artikel, die man mal lesen sollte, abarbeiten. Ich markier die einfach als Favorit und scroll in der Bahn oder so kurz durch. Laut meiner iOS Nutzungsstatistik nutze ich Reeder kaum mehr als 30 Minuten am Tag. Pro Tag kommen ca. 200 neue, ungelesene Items vorne in meinen Feed rein. Das heißt der Informationsdurchsatz ist damit erheblich beschleunigt. Ich lese selbstverständlich nicht jeden Artikel vollständig, der mir im Reeder angezeigt wird, sondern nur die, die für meine Arbeit relevant sind. Das sind vielleicht 20-30% der News.
Das ganze ist natürlich eine Bastellösung und es geht sicher noch besser. Insofern würde mich interessieren, wie ihr euern Informations-Input verwaltet.
Ja, die Korrekturspinner rauben mir auch den Nerv… Danke für den Lösungsvorschlag!
Danke für den Einblick und die Visualisierung. Ich nutze jetzt auch Feedbin und auf Android die App Readably. Das Lesen und Auswerten übernimmt die App leider noch nicht 😉